
七个RAG工程应用中的常见故障点
> 论文地址:https://arxiv.org/abs/2401.05856
1、摘要
RAG系统的目标:
- 减少LLM的幻觉问题
- 为响应添加引用源
- 减少为原文档注释(注解、打标)的需要
2、现状
LLM的限制:
- 无法获取最新知识
- 无法获取公司内部特定的领域知识
解决这个限制的两个方法:
- Finetunin,使用特定领域数据训练LLM
- RAG
3、RAG的优势
- RAG系统能够合成与上下文相关、准确且最新的信息。
- RAG系统结合了信息检索能力和LLM的生成能力。
- 检索组件专注于从数据存储中为用户查询检索相关信息。生成组件则利用检索到的信息作为上下文,为用户查询生成答案。
4、RAG管道介绍
看下面的图就差不多了,如果连RAG管道的认知都没有的话,也不会找到这篇文章了。
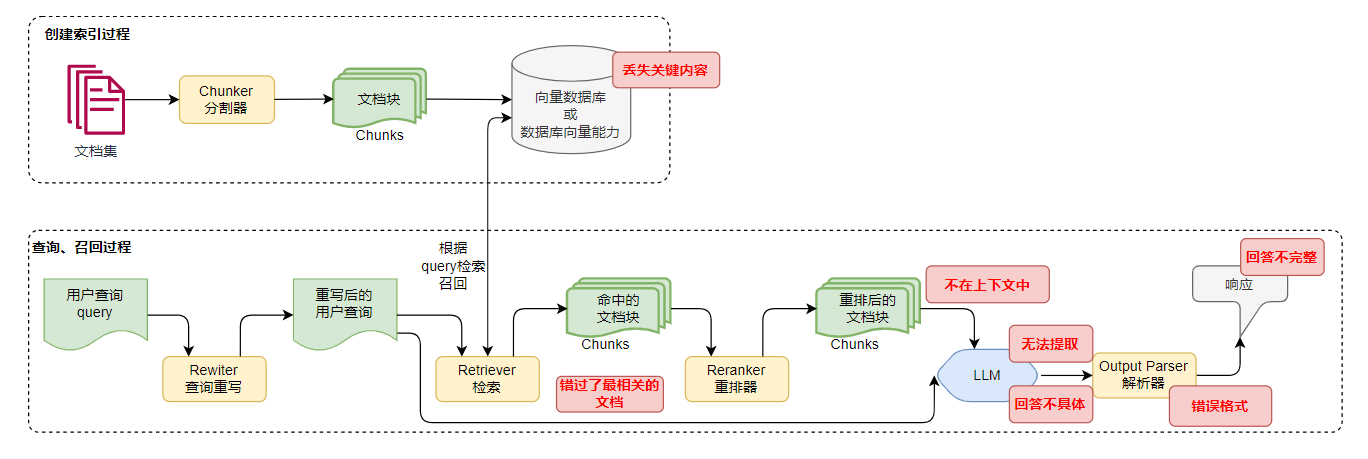
5、七个异常点
5.1、内容丢失
丢失内容( Missing Content )。
模型无法在给出的文档中获得实际的答案,比较好的情况是回答"我不知道"。
严重情况下,它会编造一个看似正确的错误答案。
这就是大模型的幻觉。
5.2、重排导致文档丢失
根据query在向量数据库中查找到了相应的文档。
但在rerank重排时,需要的文档被排在了最后。
由于大模型token的限制,需要获取Top K的文档,此时需要的文档不在Top K中。
导致文档丢失。
5.3、不在上下文中
从向量数据库中检索到了相关文档。
但在对这些文档进行后置处理(过滤、整合等操作)时,相关文档被丢弃。
最终传递给LLM的上下文中不包含相关信息。
由于相关信息不在上下文中,也有可能产生幻觉。
5.4、无法提取
相关信息在上下文中。
但由于内容太多,导致LLM无法正确提取相关信息。
或者LLM提取错误,导致回答异常。
5.5、格式错误
输出格式化错误。
错误原因可能有几种:
- 大模型自身对prompt理解有缺陷,无法正确根据prompt输出正确的格式
- 用户prompt写的不够清楚
如果对返回格式要求非常高,还需要通过工程化(对LLM响应编写特定代码解析、重组)的方式处理。
5.6、回答不够具体
特定性不准确(Incorrect Specificity) - 回答不够具体或过于具体,不能满足用户的需求。这种情况通常是因为RAG系统的设计者对于特定问题有特定的期望结果,比如教师对学生。在这种情况下,应该提供特定的教育内容,而不仅仅是答案。特定性不准确还会在用户不确定如何提问或问题过于笼统时出现。
5.7、回答不完整
不完整并不是答案时错误的,而是会漏掉一些信息。尽管这些信息都在上下文中。
这种情况通常发生在:用户问的太多,不同维度的问题放在同一个问句中,导致LLM回答有缺失。
此时好的办法是拆分用户问题,分别询问LLM,最终将问题组装返回。(LLM编排)