
Bert模型详解
1 Bert是什么?
Bert(Bidirectional Encoder Representations from Transformers)是由Google在2018年推出的一种预训练语言模型。它基于Transformer架构,特别是其中的编码器部分。与之前的模型(通常说的是RNN)不同,Bert通过双向的方式进行训练(也是Transformer的训练方式),这意味着它能够同时考虑到一个词之前和之后的上下文信息,从而更好地理解文本中的语义关系。这种特性使得Bert在多种自然语言处理任务上表现出了卓越的能力,比如问答系统、情感分析、命名实体识别等。
下面这张图详细的说明了bert在transformer中的定位。中间是完整的transformer结构,由encoder和decoder组成。Bert是encoder结构,gpt是decoder结构。
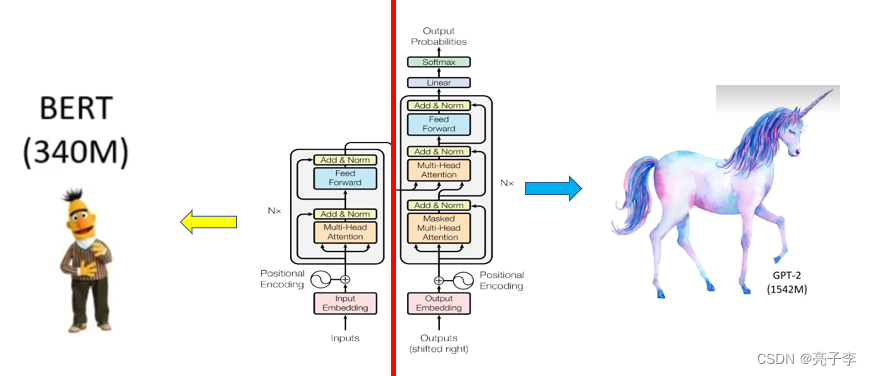
Bert完全是encoder结构,仅负责输出输入数据编码后的状态,因此Bert一般会和下游网络结合起来使用,比如在Bert后面接一个分类神经网络,则可以用来做分类任务。由于Bert基于Transformer,已经在大量的数据集上充分学习到句子之间的特征,所以比传统的神经网络分类效果要好。
2 为什么需要Bert?
- 提升性能:由于其独特的双向训练机制,Bert能够在许多NLP任务中显著提高准确率。
- 减少标注数据需求:Bert使用了大量的无标签文本进行预训练(自监督学习),然后只需要少量的标记数据(监督学习)就可以很好地适应特定的任务,这对于那些获取标注数据成本较高的领域尤其有用。监督学习、自监督学习参考👉:监督学习、无监督学习、半监督学习、自监督学习、强化学习对比分析
- 灵活性高:Bert可以很容易地被调整以适应各种不同的下游任务,只需在其顶部添加一个简单的额外层(一般添加全连接层、Softmax分类层)即可。
3 不同Bert模型的特性及选型参考
首先,我们来看下google发布的十几款bert模型,它们在命名上的规律。
这里整理了一张表格,用于说明命名规律,可用作选型参考。
| 区别类型 | 说明 |
|---|---|
| \\Base vs. Large\\ | \Base\ 模型有 110M 参数,\Large\ 模型有 340M 参数。\Large\ 模型更精确,但计算成本更高。 |
| \\Cased vs. Uncased\\ | \Uncased\ 模型不区分大小写,\Cased\ 模型区分大小写,适用于大小写重要的任务(如人名识别)。 |
| \\Whole Word Masking\\ | \Whole Word Masking\ 在预训练时掩盖整个词语,而不仅仅是子词,适用于问答、生成任务。 |
| \\Multilingual\\ | \Multilingual\ 模型支持多语言,适用于跨语言的 NLP 任务。 |
| \\专用语言模型\\ | 一些模型针对特定语言(如中文、德语)进行了优化,适用于特定语言的任务。 |
以上是google发布的Bert模型,它们在预训练的方法上基本保持了统一。
随着Bert模型的发布,后续在预训练的方法上有了不少创新,不断刷新Bert模型的性能记录。
这里同样整理了一张表格,说明不同Bert模型的特性。
| 模型 | 参数量 | 推理速度 | 模型精度 | 适用场景 | 备注 | 是否对比采用 |
|---|---|---|---|---|---|---|
| bert | 0.11B | 慢 | 高 | 适用各类NLP任务 | 预训练:MLM+NSP、16G训练数据 12layers | ❌ |
| bert-chinese-wwm | 0.11B | 慢 | 高 | 适用中文NLP任务 | 预训练:WWM+NSP 12layers WWM全词掩码,对中文友好 | ✅ |
| DistilBERT | 0.066B | 快 | 低 | 实时推理、移动端应用 | 预训练:MLM 6layers bert-base大小的66%,bert-base准确率的97% | ❌ |
| RoBERTa RoBERTa-wwm | 0.125B | 慢 | 更高 | 高精度任务(如问答、阅读理解) | 预训练:WWM、更大的训练数据集(160G)、更大的训练批次、动态掩码 12layers 性能比bert提高了 2-20% | ✅ |
| DeBERTa | 0.22B | 高 | 中等 | 高精度需求任务 | 预训练:解耦注意力机制(内容编码和位置编码分别计算attention)、更大的训练数据集(160G) 12layers | ✅ |
| ALBERT | 0.012B | 慢 | 高 | 内存敏感任务 | 预训练:跨层数参数共享(12层MHA共享权重) 12layers 和bert-base差不多,只降参数量、不降计算量 | ❌ |
| ERNIE 3.0 | 10B | 慢 | 高 | 高精度需求任务 | 预训练:融合自回归网络和自编码网络 48layers | 待定 |
ps:
关于bert模型对比的详细说明可参考HuggingFace上Bert模型区别Bert模型后面的ext代表什么?各类bert模型的对比适用中文的bert模型
关于什么是MLM、WWM,可参考Bert在预训练时,为什么需要MASKBert的MLM和WWM区别
4 Bert微调分类任务的模型结构
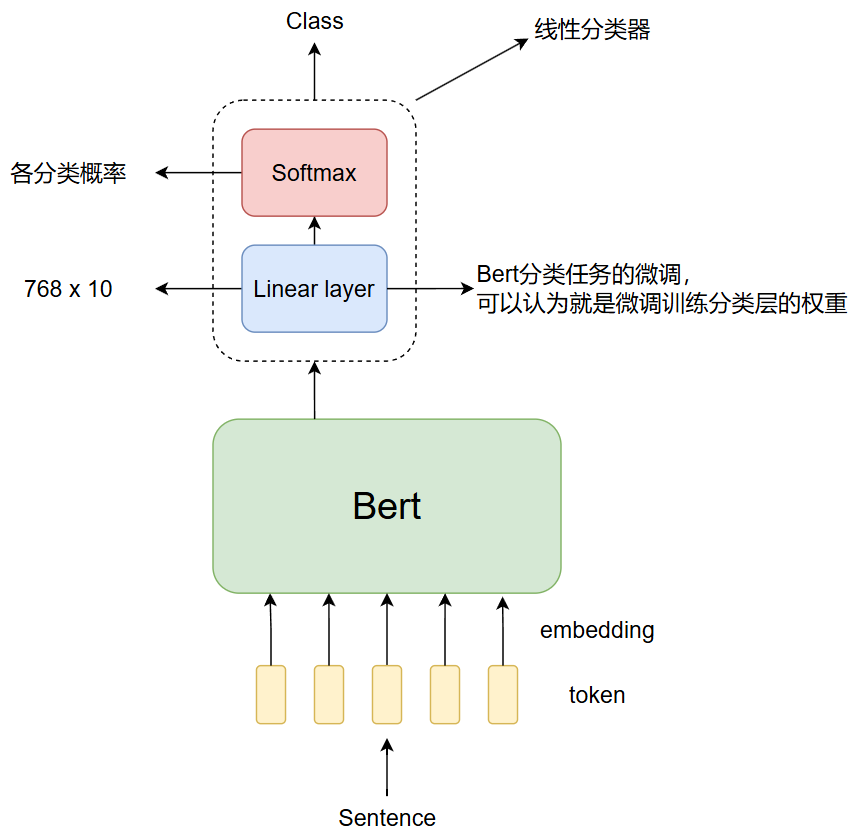
下图是在Bert基础上,微调出一个新的分类模型的结构示意图:
- 一个句子进入新的模型后,首先会被分割成token序列。
- token序列经过embedding后,会输出浮点数矩阵,假设是768维的embedding。
- 浮点数矩阵经过Bert(也就是Transformer的Encoder阵列)后,会输出768维的向量。
- 768维向量此时可以看作是输入Sentence的特征序列,大白话就是Bert从输入中提取出来了语句的特征,这些特征包括token与token之间的特征,token位置的特征等。
- 输出的768维特征,会经过线性分类器,可以简单看成是逻辑回归的神经网络,这里假设是10分类任务。因此线性层的维度是768x10。
- 线性层输出各个分类的概率后,经过Softmax(保证输出的概率和为1,常用于多分类)归一化处理,最终输出概率最大的分类。
- 在整个训练过程当中,Bert是直接调用已经预训练的模型,因此可以认为训练时,参数是冻结的。而线性分类器的参数,会随着训练迭代逐渐优化,因此,整个任务可以看成是对线性分类器权重的微调。这也就是迁移学习,将bert学习的知识,迁移到一个新的分类模型当中。
5 Bert分类任务微调QuickStart
5.1 数据准备
准备好如下几份数据:
- train.txt:训练数据,两列,text、label
- test.txt:测试数据,两列,text、lable
- class.txt:分类索引对应的真实标签
5.2 分类模型训练
引入必要的依赖包
import os
import random
import time
import numpy as np
import pandas as pd
import torch
from torch import nn
from torch.optim import Adam
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
from transformers import BertModel
from transformers import BertTokenizer
加载训练集、测试集、分类标签
train_data_path = '../data/Content_Store/006_game_first_tag_train_data.txt'
dev_data_path = '../data/Content_Store/006_game_first_tag_test_data.txt'
test_data_path = '../data/Content_Store/006_game_first_tag_test_data.txt'
label_path = '../data/Content_Store/first_tag_class.txt'
train_df = pd.read_csv(train_data_path, sep='##\$\$&&', header=None)
dev_df = pd.read_csv(dev_data_path, sep='##\$\$&&', header=None)
test_df = pd.read_csv(test_data_path, sep='##\$\$&&', header=None)
new_columns = ['text', 'label']
train_df = train_df.rename(columns=dict(zip(train_df.columns, new_columns)))
dev_df = dev_df.rename(columns=dict(zip(dev_df.columns, new_columns)))
test_df = test_df.rename(columns=dict(zip(test_df.columns, new_columns)))
real_labels = []
with open(label_path, 'r') as f:
for row in f.readlines():
real_labels.append(row.strip())
train_df.shape, dev_df.shape, real_labels
查看训练集数据
train_df.head(10)
分词器加载,自定义数据集,对输入数据tokenizer,就是对输入数据进行embedding
BERT_PATH = '../modules/chinese-roberta-wwm-ext'
tokenizer = BertTokenizer.from_pretrained(BERT_PATH)
class MyDataset(Dataset):
def __init__(self, df):
self.texts = [
tokenizer(
text,
padding='max_length',
max_length=512,
truncation=True,
return_tensors="pt"
)
for text in df['text']
]
self.labels = [label for label in df['label']]
def __getitem__(self, idx):
return self.texts[idx], self.labels[idx]
def __len__(self):
return len(self.labels)
train_dataset = MyDataset(train_df)
dev_dataset = MyDataset(dev_df)
test_dataset = MyDataset(test_df)
定义基于RoBerta的新的分类模型
class RoBertaClassifier(nn.Module):
def __init__(self):
super(RoBertaClassifier, self).__init__()
self.bert = BertModel.from_pretrained(BERT_PATH)
self.dropout = nn.Dropout(0.5)
self.linear = nn.Linear(768, 8)
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids=input_id, attention_mask=mask, return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer
epoch = 5
batch_size = 32
lr = 2e-5
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
random_seed = 1999
save_path = './roberta_wwm_content_store_checkpoint'初始化网络参数,定义保存模型方法
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
setup_seed(random_seed)
def save_model(save_name):
if not os.path.exists(save_path):
os.makedirs(save_path)
torch.save(model.state_dict(), os.path.join(save_path, save_name))
## model.save_pretrained(os.path.join(save_path, save_name))
## tokenizer.save_pretrained(os.path.join(save_path, save_name))
定义损失函数和梯度迭代优化器
model = RoBertaClassifier()
if torch.cuda.device_count() > 1:
print(f"使用 {torch.cuda.device_count()} 张 GPU!")
model = nn.DataParallel(model)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=lr)
model = model.to(device)
criterion = criterion.to(device)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
实际训练过程
best_dev_acc = 0
for epoch_num in range(epoch):
total_acc_train = 0
total_loss_train = 0
for inputs, labels in tqdm(train_loader):
## 获取ids和mask,这些是transformer的输入
input_ids = inputs['input_ids'].squeeze(1).to(device)
masks = inputs['attention_mask'].to(device)
labels = labels.to(device)
## 计算新的分类模型的输出值
output = model(input_ids, masks)
batch_loss = criterion(output, labels)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
acc = (output.argmax(dim=1) == labels).sum().item()
total_acc_train += acc
total_loss_train += batch_loss.item()
## 模型置为验证模式,不影响训练过程
model.eval()
total_acc_val = 0
total_loss_val = 0
with torch.no_grad():
for inputs, labels in dev_loader:
input_ids = inputs['input_ids'].squeeze(1).to(device)
masks = inputs['attention_mask'].to(device)
labels = labels.to(device)
output = model(input_ids, masks)
batch_loss = criterion(output, labels)
acc = (output.argmax(dim=1) == labels).sum().item()
total_acc_val += acc
total_loss_val += batch_loss.item()
print(f'''Epochs: {epoch_num + 1}
| Train Loss: {total_loss_train / len(train_dataset): .3f}
| Train Accuracy: {total_acc_train / len(train_dataset): .3f}
| Val Loss: {total_loss_val / len(dev_dataset): .3f}
| Val Accuracy: {total_acc_val / len(dev_dataset): .3f}''')
if total_acc_val / len(dev_dataset) > best_dev_acc:
best_dev_acc = total_acc_val / len(dev_dataset)
## save_model(model, tokenizer, 'best_' + str(best_dev_acc) + '_' + str(int(time.time())))
save_model('best.pt')
model.train()
save_model('last.pt')最终的结果可以看到,train loss在逐步递减,但是验证集精度在第2个epoch就已经到顶了,说明后面的epoch已经过拟合了,我们使用第2个epoch训练出来的模型就行了。
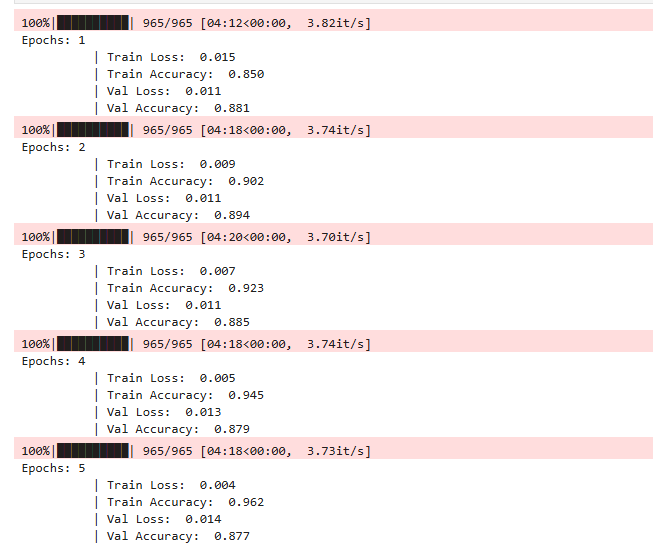
模型评估,由于我们使用的验证集和测试集使用相同数据集,因此这里输出和上述第2个epoch保持一致。
model = RoBertaClassifier()
if torch.cuda.device_count() > 1:
print(f"使用 {torch.cuda.device_count()} 张 GPU!")
model = nn.DataParallel(model)
model.load_state_dict(torch.load(os.path.join(save_path, 'best.pt')))
model = model.to(device)
model.eval()
def evaluate(model, dataset):
model.eval()
test_loader = DataLoader(dataset, batch_size=128)
total_acc_test = 0
with torch.no_grad():
for test_input, test_label in test_loader:
input_id = test_input['input_ids'].squeeze(1).to(device)
mask = test_input['attention_mask'].to(device)
test_label = test_label.to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
total_acc_test += acc
print(f'Test Accuracy: {total_acc_test / len(dataset): .3f}')
evaluate(model, test_dataset)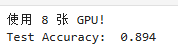
新的分类模型加载,测试
while True:
text = input('APP内容:')
bert_input = tokenizer(
text,
padding='max_length',
max_length=512,
truncation=True,
return_tensors="pt"
)
input_ids = bert_input['input_ids'].to(device)
masks = bert_input['attention_mask'].unsqueeze(1).to(device)
output = model(input_ids, masks)
pred = output.argmax(dim=1)
print("标签索引:" + str(pred))
print("标签:" + str(real_labels[pred]))
6 真实分类场景下的Bert+SFT\&LLM+Prompt对比
通过搭建一个fast api的web服务,加载训练好的模型,然后在原有800个游戏APP上进行分类,执行速度如下所示:
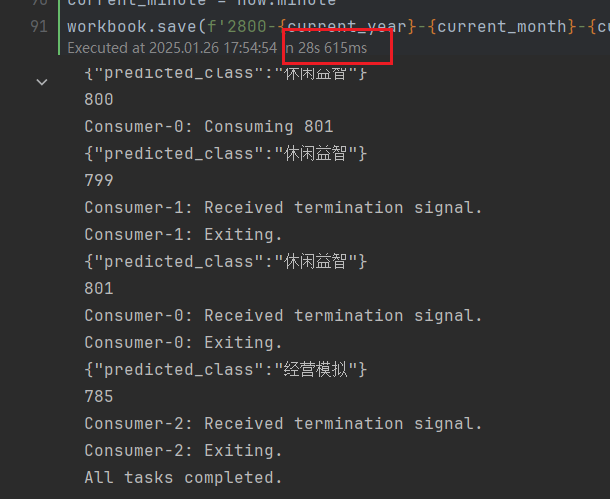
最终执行时间仅用时28s,相较于LLM+Prompt,执行时间降低96%(40min->1.5min,三级标签识别需要调用3次模型)
准确率如下:
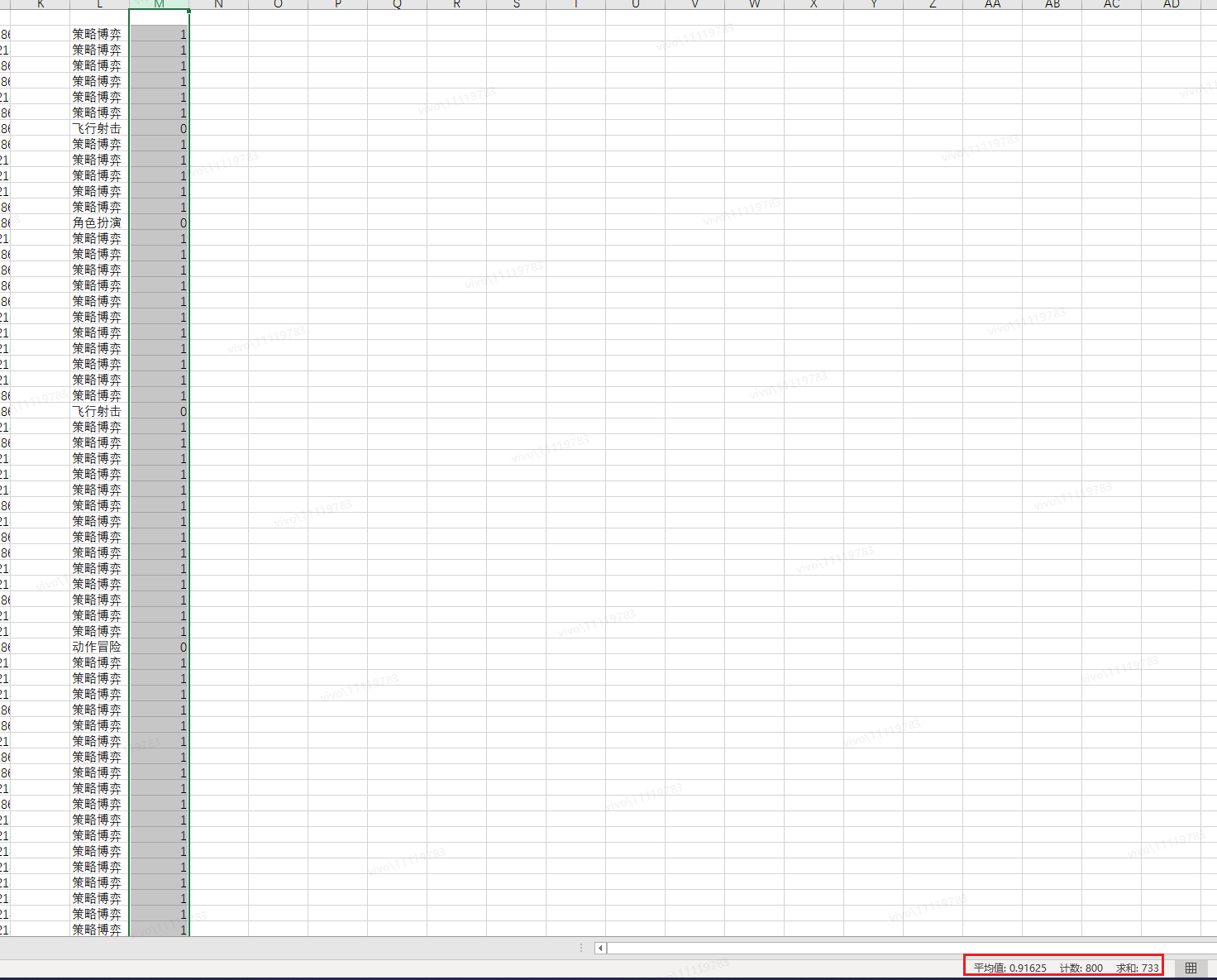
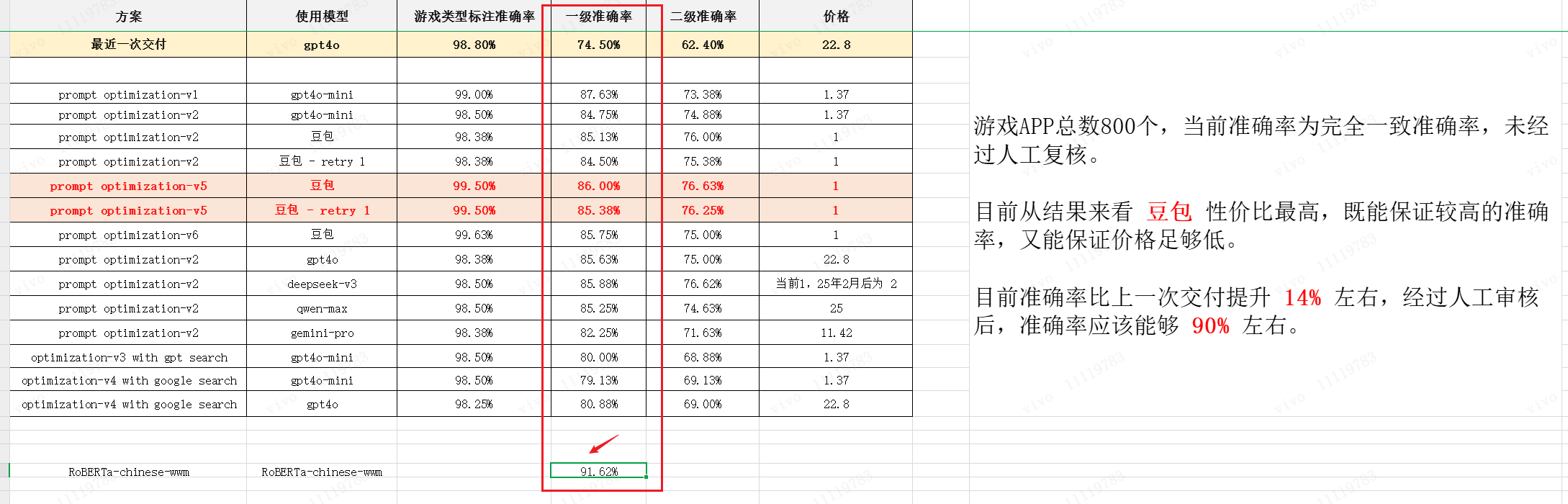
7 后续规划
目前可以认为Bert模型微调,能够在分类场景下,带来执行效率、执行准确率的提升,同时还能够降低模型应用成本。Roberta-Chinese-wwm基本满足我们的分类场景,可以先应用,后续再调研相同量级的其他模型,看看是否能在准确率和执行效率(除非考虑一些实时场景,否则目前执行效率完全够用)上进一步的提升。因此,后续可能有以下一些需要做的事:
- 考虑如何快速集成训练好的模型,模型测web服务,然后以插件的形式集成?后续这类场景多了如何处理?
- 调研更加有潜力的模型,提升整体分类准确率。
- Bert模型不同应用场景的探索,比如Bert在问答系统、情感分析、命名实体识别的应用。